Building RAG-based LLM Applications with LangGraph
In this article, I'll share my experience building Retrieval-Augmented Generation (RAG) systems using LangGraph for document management platforms and real estate applications like ChatImmo.
Introduction to RAG
Retrieval-Augmented Generation (RAG) is a technique that enhances Large Language Models (LLMs) by providing them with relevant external knowledge. Instead of relying solely on the knowledge encoded in the model's parameters, RAG systems retrieve information from a knowledge base before generating responses, resulting in more accurate and up-to-date outputs.
Why LangGraph?
LangGraph is a powerful framework for building complex, stateful LLM applications. It extends LangChain with the ability to create directed graphs where nodes can be LLM calls, tools, or other operations. This makes it particularly well-suited for RAG applications that require multiple steps of reasoning, retrieval, and generation.
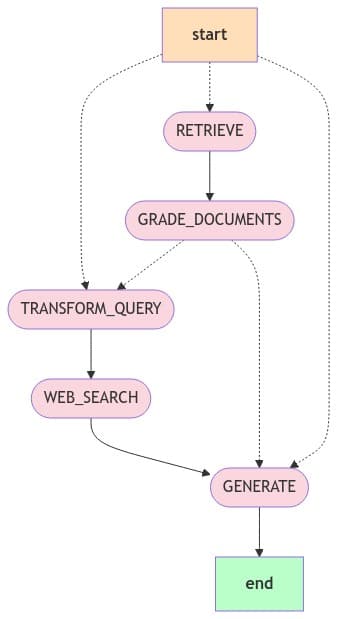
Graph Architecture Overview
At its core, LangGraph allows us to model complex AI workflows as directed graphs. This approach offers several advantages:
- Explicit Flow Control: Clear visualization and management of complex decision paths
- State Management: Maintaining context across multiple interactions
- Modularity: Easily replaceable components for different use cases
- Debugging: Ability to trace execution through each node
A typical LangGraph-based RAG architecture includes the following nodes:
1. Query Understanding Node
This node analyzes the user's query to:
- Determine the intent and extract key information
- Identify required knowledge domains
- Formulate an effective retrieval strategy
- Decide if retrieval is necessary at all
2. Query Transformation Node
Often, the original query isn't optimal for retrieval. This node:
- Expands queries with synonyms and related terms
- Breaks complex queries into sub-queries
- Reformulates questions for better retrieval
- Generates multiple query variations
3. Retrieval Node
This critical node fetches relevant information:
- Performs vector similarity search
- Applies filters based on metadata
- Ranks and selects the most relevant documents
- Handles hybrid retrieval (combining semantic and keyword search)
4. Context Integration Node
Retrieved information needs to be processed before generation:
- Merges information from multiple sources
- Resolves contradictions
- Prioritizes information based on relevance and reliability
- Formats context for optimal LLM consumption
5. Generation Node
This node produces the final response:
- Crafts prompts that effectively use the retrieved context
- Generates coherent, accurate responses
- Cites sources appropriately
- Maintains the desired tone and style
6. Evaluation Node
Quality control is essential:
- Assesses response quality and relevance
- Checks for factual accuracy against retrieved context
- Identifies hallucinations or unsupported claims
- Triggers additional retrieval or regeneration if needed
Example Architecture: ChatImmo Real Estate Assistant
For the ChatImmo project, we implemented a specialized LangGraph architecture tailored for real estate queries:
Architecture Components
The system included several specialized nodes:
- Intent Classification Node: Categorizes queries into property search, market analysis, document review, etc.
- Property Search Node: Handles structured search for properties matching specific criteria
- Market Analysis Node: Retrieves and processes historical price data and trends
- Document Analysis Node: Extracts key information from property documents
- Multilingual Processing Node: Handles translation and language-specific nuances
- Response Generation Node: Creates natural, helpful responses in the user's preferred language
Implementation Example
Here's a simplified example of how we implemented the ChatImmo graph structure:
from langchain.graphs import StateGraph
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import Document
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.tools import Tool
# Define the nodes
def intent_classifier(state):
query = state["query"]
llm = ChatOpenAI(temperature=0)
prompt = ChatPromptTemplate.from_template(
"Classify the following real estate query into one of these categories: "
"PROPERTY_SEARCH, MARKET_ANALYSIS, DOCUMENT_REVIEW, GENERAL_QUESTION.
"
"Query: {query}
Category:"
)
response = llm.invoke(prompt.format(query=query))
return {"intent": response.content.strip()}
def query_transformer(state):
query = state["query"]
intent = state["intent"]
llm = ChatOpenAI(temperature=0.2)
prompt = ChatPromptTemplate.from_template(
"Transform the following real estate query for better retrieval. "
"The query intent is {intent}.
"
"Original query: {query}
"
"Transformed query:"
)
response = llm.invoke(prompt.format(query=query, intent=intent))
return {"transformed_query": response.content.strip()}
def retriever(state):
transformed_query = state["transformed_query"]
intent = state["intent"]
# Different retrieval strategies based on intent
if intent == "PROPERTY_SEARCH":
# Structured property database search
results = property_db.search(transformed_query)
elif intent == "MARKET_ANALYSIS":
# Time-series data retrieval
results = market_data.get_trends(transformed_query)
elif intent == "DOCUMENT_REVIEW":
# Document vector search
results = document_vectorstore.similarity_search(transformed_query)
else:
# General knowledge retrieval
results = general_vectorstore.similarity_search(transformed_query)
return {"retrieved_documents": results}
def response_generator(state):
query = state["query"]
retrieved_documents = state["retrieved_documents"]
# Format context from retrieved documents
context = "
".join([doc.page_content for doc in retrieved_documents])
llm = ChatOpenAI(temperature=0.7)
prompt = ChatPromptTemplate.from_template(
"You are a helpful real estate assistant. Answer the following query "
"based on the provided context. If you don't know the answer, say so.
"
"Context: {context}
"
"Query: {query}
"
"Answer:"
)
response = llm.invoke(prompt.format(query=query, context=context))
return {"response": response.content.strip()}
# Create the graph
workflow = StateGraph(name="RealEstateRAG")
# Add nodes
workflow.add_node("intent_classifier", intent_classifier)
workflow.add_node("query_transformer", query_transformer)
workflow.add_node("retriever", retriever)
workflow.add_node("response_generator", response_generator)
# Add edges
workflow.add_edge("intent_classifier", "query_transformer")
workflow.add_edge("query_transformer", "retriever")
workflow.add_edge("retriever", "response_generator")
# Set entry point
workflow.set_entry_point("intent_classifier")
# Compile the graph
app = workflow.compile()
Agent Behaviors with LangGraph
LangGraph enables sophisticated agent behaviors that go beyond simple RAG pipelines:
1. Recursive Reasoning
For complex queries, we implemented recursive reasoning patterns:
- Breaking down complex questions into simpler sub-questions
- Retrieving information for each sub-question
- Synthesizing a comprehensive answer from multiple retrievals
- Using cycles in the graph to enable iterative refinement
2. Tool Use
LangGraph agents can use tools to enhance their capabilities:
- Calculators for numerical analysis (e.g., mortgage calculations)
- External APIs for real-time data (e.g., current interest rates)
- Structured database queries for precise information retrieval
- Document parsers for extracting information from PDFs and images
3. Multi-Agent Collaboration
For EffortAgent, we implemented a multi-agent system where:
- Specialist agents focus on different aspects of content creation
- A coordinator agent manages the overall workflow
- Critic agents review and improve generated content
- The system enables "agent debates" to resolve conflicting perspectives
Real-World Applications
Case Study 1: ChatImmo Real Estate Assistant
ChatImmo demonstrates how LangGraph-based RAG can transform industry-specific applications:
- Challenge: Real estate information is complex, multi-faceted, and often requires domain expertise
- Solution: A LangGraph architecture with specialized nodes for property search, market analysis, and document review
- Results: Users can ask natural language questions about properties, markets, and legal documents, receiving accurate, contextual responses
- Key Feature: Multilingual support allows the system to serve diverse clients in their preferred language
Case Study 2: EffortAgent Content Platform
EffortAgent uses LangGraph to create a sophisticated content creation and analysis system:
- Challenge: Creating high-quality, factually accurate content requires multiple steps of research, writing, and review
- Solution: A multi-agent LangGraph system with specialized agents for research, writing, editing, and fact-checking
- Results: The platform generates comprehensive, well-researched documents with proper citations and minimal hallucinations
- Key Feature: The system can generate thought-provoking questions and answers about documents, enhancing understanding and exploration
Challenges and Solutions
1. Hallucination Management
LLMs can generate plausible but incorrect information. Our solution:
- Implementing fact-checking nodes that verify generated content against retrieved documents
- Using explicit citation mechanisms to trace claims back to sources
- Designing prompts that discourage speculation when information is unavailable
- Adding confidence scores to different parts of the response
2. Context Window Limitations
LLMs have finite context windows, limiting how much retrieved information can be used:
- Developing smart chunking strategies that preserve document structure
- Implementing relevance ranking to prioritize the most important information
- Using recursive summarization for large document sets
- Creating specialized nodes for information distillation
3. Performance Optimization
Complex graphs can introduce latency. Our optimizations included:
- Implementing caching at multiple levels (query, retrieval, generation)
- Using conditional execution to skip unnecessary nodes
- Optimizing database queries and vector search operations
- Parallelizing independent operations where possible
Future Directions
The field of LangGraph-based RAG is rapidly evolving. Some promising directions include:
- Adaptive Retrieval: Systems that learn which retrieval strategies work best for different query types
- Multimodal RAG: Incorporating images, audio, and video into the retrieval and generation process
- Personalized RAG: Tailoring retrievals and responses to individual user preferences and history
- Collaborative RAG: Systems that can work with humans in the loop for complex tasks
Conclusion
LangGraph provides a powerful framework for building sophisticated RAG applications. By structuring the application as a directed graph of operations, we can create more robust, accurate, and maintainable AI systems. Projects like ChatImmo and EffortAgent demonstrate the real-world impact of these approaches, transforming how users interact with complex information domains.
As LLM technology continues to evolve, frameworks like LangGraph will play an increasingly important role in helping developers build complex AI applications that combine the power of large language models with structured reasoning, retrieval, and domain-specific knowledge.